![]() (1)
(1)
AAPG '98 Annual Convention, Advances in Geostatistics, Salt Lake City, Utah, May 17-20, 1998.
William L. Wingle and
Eileen P. Poeter,
Colorado School of Mines,
Department of Geology and Geological Engineering
When using traditional discrete multiple indicator conditional simulation, semivariogram models are based on the spatial variance of data above and below selected thresholds (cut-offs). There are two problems though; 1) the spatial distribution of a threshold can be difficult to conceptualize, and 2) ordering of the indicators may influence the results, unfortunately to change the arbitrary order, to test sensitivity, involves substantial effort. If the conditional simulations instead are based on the indicators themselves (classes), rather than the thresholds separating the indicators, then the spatial statistics are more intuitive, and reordering the indicators becomes a trivial endeavor. When class indicators are used, the indicator order can be switched at any time without recalculating the semivariograms. If thresholds are used, and the ordering is changed, all the semivariograms must be recalculated. A final advantage of using the class approach is that semivariograms calculated from transition probabilities go directly into the simulation. Despite significant differences in the methods, the simulation results are nearly identical, for cases where ordering does not cause differences when using the threshold approach. Given the consistency resulting from the class approach and its ease of use, this approach is preferred.
Introduction
In traditional Multiple Indicator Conditional Simulation (MICS), the kriged model results are based on semivariograms describing the spatial distribution of the thresholds between indicators. The affect of the order of the indicators on the resulting realizations is rarely evaluated even though the numerical order is arbitrary. For traditional simulation, the estimated indicator at a location is based on the probability that the location is below each threshold (the number of thresholds equals the number of indicators minus one). A more intuitive approach is based on calculating the probability of occurrence of each individual indicator. This paper presents a technique which uses semivariogram models based on individual indicators (classes), as opposed to the traditional threshold semivariograms which are based on the indicators below a cut-off versus the indicators above the cut-off.
These differences can be described mathematically as follows. Where the data set has been differentiated into a finite number of indicators, it is possible to define a random function (Z(x)) whose outcomes will have values in the range zmin to zmax. From the definition of the indicators, K thresholds can be defined (K + 1 equals the number of indicators) where:
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
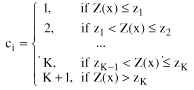 (4)
(4)
![]() (5)
(5)
![]() (6)
(6)
Because the equations to define the class or threshold expectation are fundamentally the same, the class method generates realizations that are equally accurate to threshold realizations, but with three advantages. First, it is easier to conceptually relate the model semivariograms to the spatial distribution of the geologic units. When class semivariograms are calculated, the range reflects the average size of the units, whereas the threshold semivariograms represent the distribution of indicators above or below a threshold and these can be difficult to conceptually equate to units in complex geologic settings. The first and last class and threshold semivariograms will always be identical (they are based on equivalent indicator sets), however the intermediate semivariograms may vary substantially. The intuitive sense for the threshold semivariogram range decreases with an increasing number of indicators, while Class semivariogram ranges, still reflect the average size of the unit. The second advantage to using classes is that sensitivity to indicator ordering can be evaluated without developing additional semivariogram models. If thresholds are used, the full suite of threshold semivariogram models must be recalculated for each reordering. The final advantage is that semivariograms can be calculated for transition probabilities (Carle and Fogg, 1996). The class approach does have several disadvantages: 1) more order relation violations occur, though because of the techniques utilized with thresholds, some of these may simply not be visible, though present, 2) it is computationally more expensive (one additional kriging matrix must be solved per grid cell), and 3) it requires one additional semivariogram model definition. The last two items are only a concern, if ordering sensitivity is not evaluated. If sensitivity to ordering is a concern, preparation for the threshold method requires far more human effort and computer time to develop and analyze the additional semivariogram models.
Methods
To use classes, the threshold simulation process is modified at the data definition level, and in the evaluation of the kriged CDF.
Data Definition
To calculate a threshold indicator semivariogram, an individual threshold is selected. All values below the threshold are assigned a 1, and values above the threshold are assigned a 0. For class semivariograms, locations with sample values that are in the class being evaluated are set to 1, the remaining values are set to 0.
If imprecise soft data are used (data with non-negligible uncertainty), with associated misclassification probabilities, the following steps are required. First, the probability that the data correctly, or incorrectly, reflect the class is defined using misclassification probabilities (p1 and p2):
Using indicator thresholds, p1 and p2 are determined by measuring the ability of soft information to correctly classify the hard training set data above and below a specified threshold level. The misclassification probabilities are defined as:
![]() (7)
(7)
![]() (8)
(8)
![]() (9)
(9)
![]() (10)
(10)
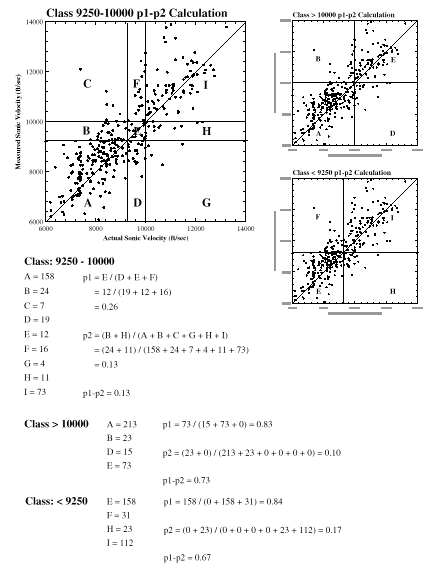
Difference Between Prior Hard and Prior Soft Data CDF's for Class and Threshold Simulations
An additional and important difference between class and threshold simulation is the definition and treatment of the difference in the hard data and soft data prior probability distributions. Often, hard and soft data collection techniques suggest different percentages of each indicator occurring at the site. If the simulator uses thresholds, the correction term is based on:
If classes are used, the correction term is based on:
The difference is subtle, but important. For the threshold approach, if the probability of a single threshold varies significantly between the hard and soft data, the importance of the remaining thresholds can be under-valued. Reordering the indicators can alleviate some of this problem. For the class approach, the relative occurrence of each indicator is directly compared, therefore when one class has very different prior hard and prior soft probabilities, it does not seriously affect other class estimates, because the error is not cumulative.
Order Relation Violations
As with traditional threshold simulation, the class CDF for a particular grid location may not be monotonically increasing and may not sum to 1.0. These are order relation violations (ORV's). They can be caused by use of inconsistent semivariogram models for the different thresholds or classes, or by use of different prior probabilities and p1-p2 weights applied to soft data. Threshold and class methods manage ORV's differently, due to differences in how the CDF's are generated, and technical difficulties in reducing the threshold CDF to a PDF.
One type of ORV occurs when the CDF declines from one threshold to the next (Figure 2a). A CDF is a cumulative probability, so a declining CDF is an impossibility. It is not possible to determine which threshold causes the problem, therefore to remedy the situation, the average of the two probabilities is assigned to both thresholds. For classes, the equivalent problem is an individual class having a negative probability of occurrence (Figure 2b: indicator #2), which is also an impossibility. In this case though, it is reasonable to assign that class a zero probability of occurrence. There is no reason to distribute the error to another unrelated indicator.
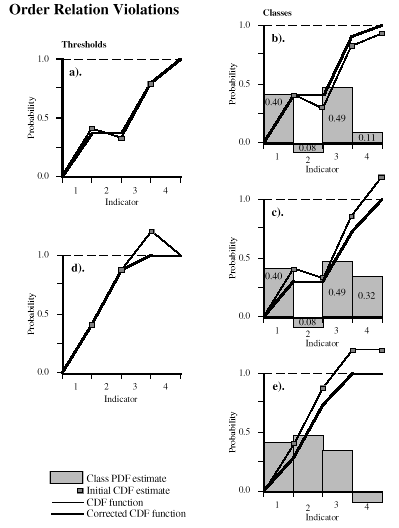
These techniques for managing class ORV's are less biased then the threshold method. This is fortunate, since the class method also produces more ORV's. However, these additional ORV's are basically ignored by the threshold approach (compare Figures 2a vs. 2c).
Conclusions
Class simulation has significant advantages over threshold simulation:
Acknowledgments
We appreciate the United States Army Corps of Engineers, Waterways Experiment Station for supporting this research.
References
Alabert, F.G., 1987, Stochastic Imaging and Spatial Distributions Using Hard and Soft Information. Master's Thesis, Department of Applied Earth Sciences. Stanford, Stanford University.
Carle, S.F. and G.E. Fogg, 1996, ``Transition Probability-Based Indicator Geostatistics.'' Mathematical Geology, Vol. 28, No. 4, pp. 453-476.
Gómez-Hernández, J.J. and R.M. Srivastava, 1990, ``ISIM3D: An ANSI-C Three Dimensional Multiple Indicator Conditional Simulation Program.'' Computers in Geoscience, Vol. 16, No. 4, pp. 395-440.
Journel, A.G. and C.J. Huijbregts, 1978, Mining Geostatistics. London, Academic Press.